Understanding Lambda Architecture in Modern Data Engineering:
What is Lambda Architecture?
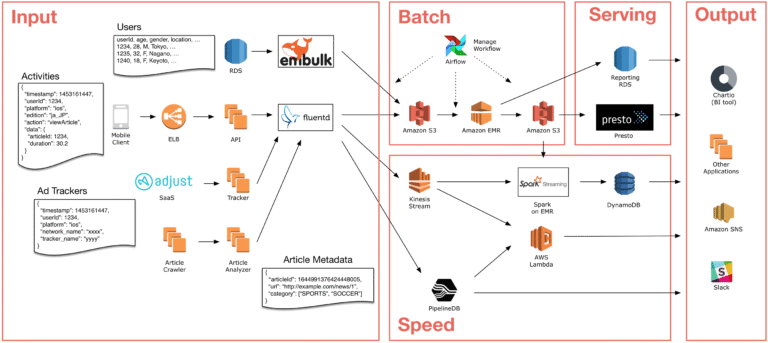
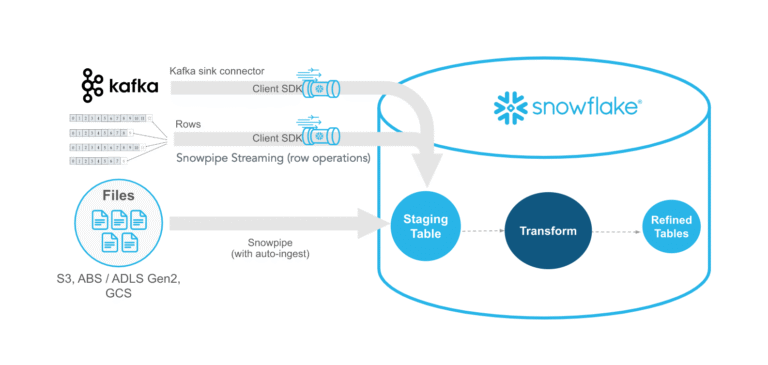
I only recently came across this type of data architecture and to fair I have been using it without even realising that it had a specific type of name to it. I was actually asked about this during an interview and I was immediately stunned as I usually have an inclination to what something is particularly when it comes to data warehouse or data lakes. I previously had worked on architecture which involved batch and realtime data using aurora for OLTP and snowflake for OLAP which I shall cover on a later date.
Lambda Architecture is a data-processing design pattern that combines batch processing and real-time stream processing to provide both scalability and low-latency insights.
It was introduced to solve the challenge of balancing:
Accuracy & completeness (batch layer)
Speed & freshness (speed/streaming layer)
This dual-layer model ensures businesses can react to real-time events while still maintaining a “single source of truth” with historical data.
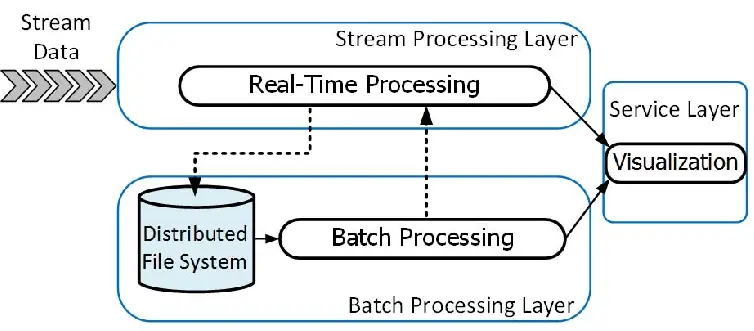
1. The Three Layers of Lambda Architecture
Batch Layer
Stores the master dataset (immutable, append-only raw data).