
When I first started revising for the SnowPro Core Certification, one of the most helpful approaches was to step back and ask a very simple question: why does Snowflake exist, and what makes it different from the databases and data warehouses that came before it?
At its core, Snowflake is a cloud-native data platform. Unlike traditional databases that were either hardware-bound or required heavy tuning, Snowflake is delivered as a fully managed Software-as-a-Service (SaaS). That means no installation, no patching, no maintenance windows — everything runs on the public cloud (AWS, Azure, or GCP). Importantly, Snowflake has no on-premises or hybrid option; you run it fully in the cloud, with your account hosted inside a dedicated VPC provided by Snowflake.
So why has it become such a dominant player? The answer lies in a few key design principles:
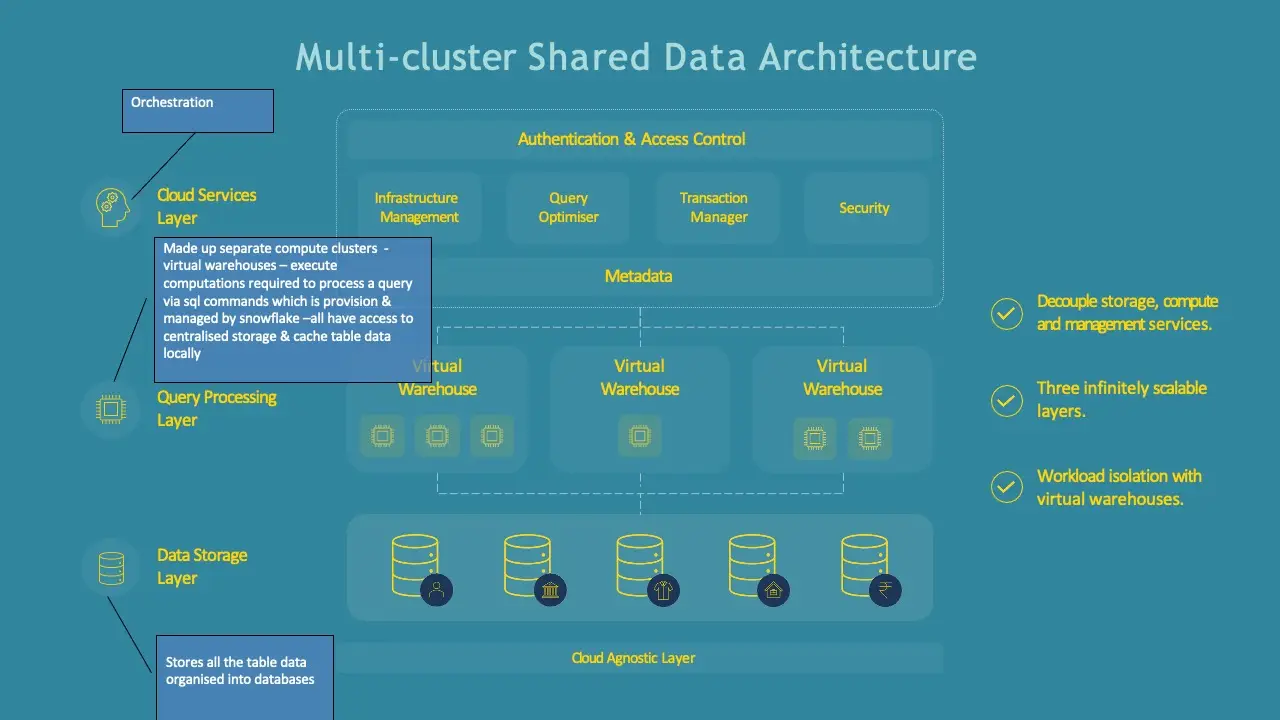
One of the biggest challenges with legacy systems was that compute and storage were tightly coupled. If you needed more processing power, you also ended up paying for more storage, and vice versa. Snowflake breaks this by decoupling compute from storage.
Storage: All data is stored centrally in a compressed, columnar format, organised into micro-partitions (think of them as small, immutable chunks of data).
Compute: Queries are run using Virtual Warehouses, which are clusters of compute resources. These can be scaled independently — both in size (vertical scaling) and in number of clusters (horizontal scaling).
Result: You can scale up a warehouse for a heavy job, or add more clusters for concurrent users, without duplicating data or affecting other workloads.
This architectural choice is why Snowflake is often described as a hybrid of shared-disk and shared-nothing architectures
Snowflake brings true elasticity. Warehouses can automatically suspend when idle (saving credits) and resume instantly when needed. They can also scale horizontally with multi-cluster warehouses to handle spikes in concurrent queries.
From a revision perspective, remember:
Warehouses are billed by the second (minimum of 60s).
Auto-suspend and auto-resume are crucial best practices to control costs.
This is part of what makes Snowflake feel effortless compared to older platforms that required DBAs to constantly monitor workloads and tune performance.
On top of compute and storage sits the Cloud Services layer — the “brain” of Snowflake. This is where critical operations are handled, such as:
Authentication & security (MFA, SSO, federated auth)
Metadata management (keeping track of micro-partitions, queries, and results)
Query parsing and optimisation
Access control and governance
An important exam takeaway: you cannot see or modify this layer. It’s shared across customers (unless you pay for a Virtual Private Snowflake edition), and it ensures the “as-a-service” nature of the platform.
Truly SaaS: No hardware, no software installs, and no upgrades to manage.
Multi-cloud: Available on AWS, Azure, and GCP, with region-based deployments.
Performance: Columnar storage + micro-partitions + query optimiser means high efficiency.
Flexibility: Supports structured and semi-structured data (JSON, Parquet, ORC, Avro).
Concurrency: Multiple virtual warehouses can operate on the same data without contention.
Security: End-to-end encryption, role-based access control, and advanced compliance (HIPAA, PCI DSS, SOC) in higher editions.
Snowflake is cloud-only SaaS; no on-premises or hybrid options.
Key differentiator: separation of compute, storage, and services.
Warehouses = compute clusters; storage is centralised, compressed, and columnar.
Cloud Services layer manages metadata, security, and optimisation.
Elasticity = scale up/out, auto-suspend/resume.
Every feature — from micro-partitions to multi-cluster warehouses — ties back to the same principle: making data storage and analytics simple, elastic, and cloud-native..