Inside AWS Aurora: Key Takeaways from an In-Depth Technical Workshop
From architecture and Serverless v2 to Blue/Green deployments, Zero-ETL, I/O-Optimized storage, and Limitless Database — here’s what stood out and how it applies to real workloads.
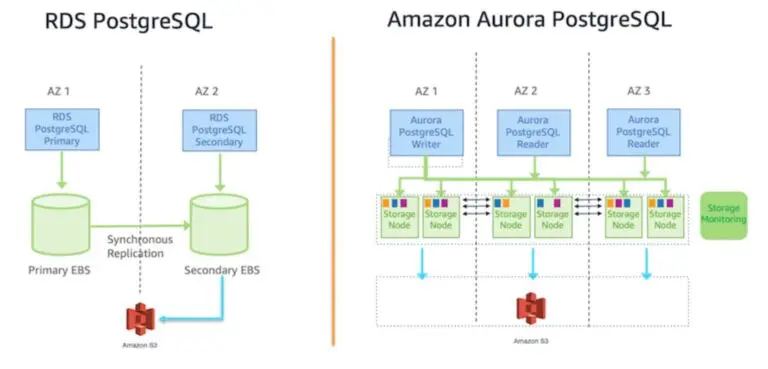
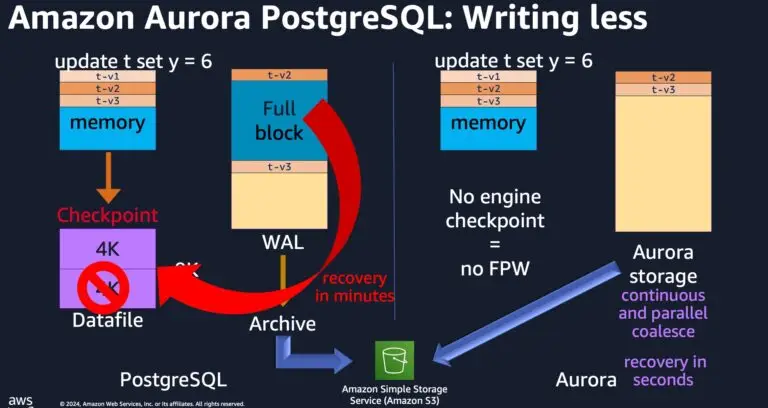
Aurora is a cloud-native database that separates compute from storage and replicates data six ways across three Availability Zones. Unlike vanilla PostgreSQL, Aurora avoids full-page writes during checkpoints, significantly reducing I/O and enabling much faster recovery by reconstructing from Amazon S3 in parallel.
Why it matters: You get high durability and fast crash recovery without the operational burden of complex storage tuning.
2. Serverless v2 - Capacity Without the Guesswork
On-demand, fine-grained scaling with per-second billing.
Auto-pause to zero ACUs for dev/test when connections are idle.
Dynamic buffer pool resizing using LFU/LRU eviction.
Auto-pause is bypassed when connections remain open, RDS Proxy is used, Global DB is enabled, or logical replication is on.
Tip: For non-prod clusters, set min capacity to 0 ACUs and a short pause timeout to save costs.